
During our roundtable discussion at an AIIM Conference, we shared our stories and experiences to help identify best practices for processing unstructured documents and content. We tried our best to not get into Ph.D. level discussions as we only had 45 minutes, and would probably lose a few people if we did that.
We spent a few minutes describing the topic and then provided stories of extracting data from unstructured documents based on our own experience.
Unstructured documents or content refers to information that does not have a well-defined or organized data model. This results in ambiguities and irregularities that make it challenging to understand programmatically and process the content. It takes years of observation and programming for the most powerful computer, our human brain, to be able to process the unstructured content. Moreover, it typically requires further training to target and process specifics from unstructured content. The good news is that if your brain can process it then there must be some implied structure and rules (we will get into some details later).
That said, approximately 75% of all potentially valuable business information originates in unstructured form. Today there are around 38 Zettabytes (10e21) of unstructured content available for processing. This number is growing rapidly as we continue to become a digital society. Typically, the content of unstructured data is extracted via trained humans. These humans have cost and time implications that require an immediate or known return on investment.
The Content Itself Breaks Down Into A Number Of Categories.
Content, Document, and Process types and Technologies to manage this array of data models.
Content Types:
- Paper but not just paper
- Websites
- Electronic documents
Documents Types:
- Contracts
- Mortgage documents
- Claims
- Customer correspondence
- Healthcare EOBs
- Proposals
- Social media
Business Processes:
- Simple search/locate
- Analytics/Business Intelligence
- Customer service/sentiment analysis
- Case management
- Legal discovery
- Report generation
Technologies:
- Data Entry
- Text Analytics/Word Bags (Simplest form: Search Engine, Word counting, content tagging (People, places, objects, addresses, dates, etc.)
- Natural Language Processing (Clustering | JacardDistance | nGram | Lexicon |Grammar POS | Dictionary Lookup)
- Machine Learning (That explores the construction and study of algorithms that can learn from data)
How Can You Use Technology To Extract The Data
Algorithms can infer inherent structure from the text, for instance, by examining word morphology, sentence syntax, and other small- and large-scale patterns. Unstructured information can then be enriched and tagged to address ambiguities and relevancy-based techniques can then be used to facilitate search and discovery
NLP Difficulties:
- The lady boarded the plane with bags. (really meant that a lady with a bag boarded the plane)
- The old man the boat. (The boat is manned by the old)
- The horse raced past the barn fell. (A British reader would interpret as raced past a dreadful barn where others would stumble and fell and determine the horse itself fell)
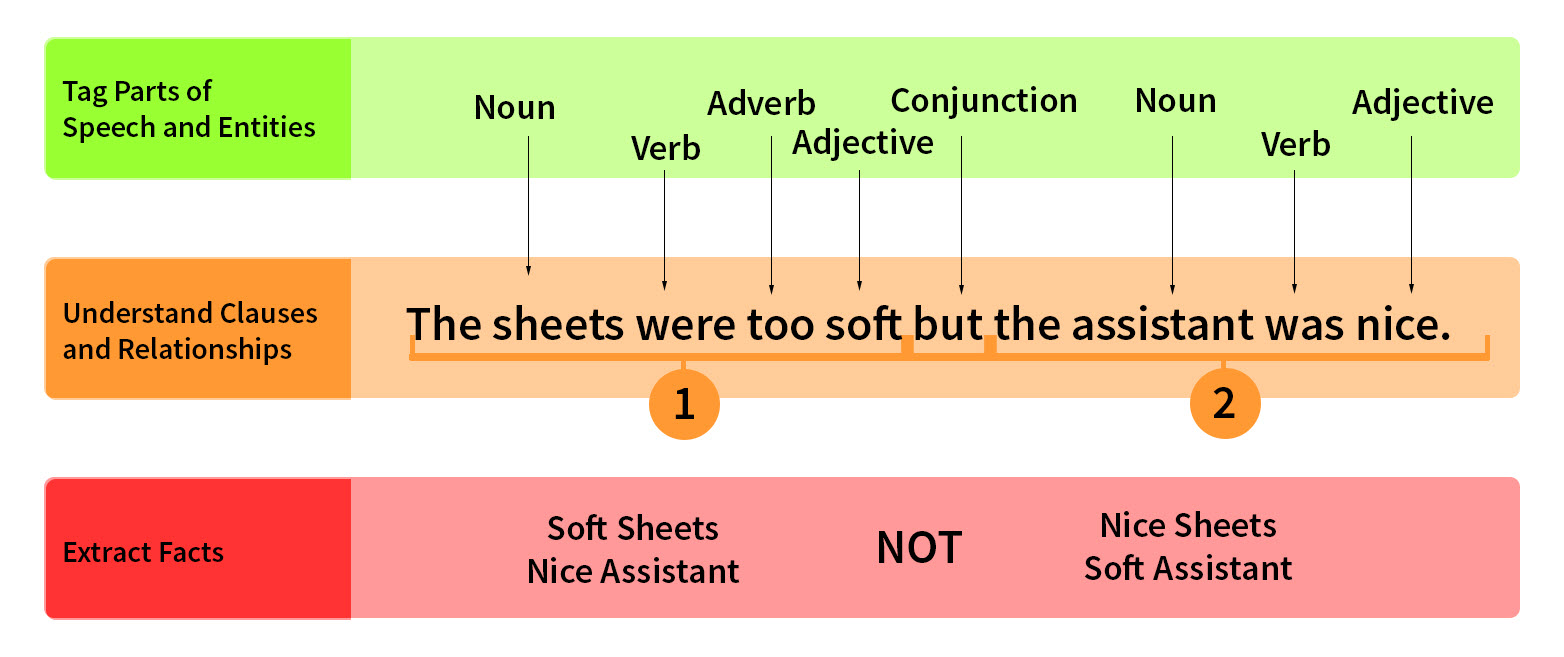
As you can see, even using advanced software can have its challenges but as we learn as humans, so does our software.
Software Designed For Your Toughest Document Challenges.
Axis AI, our flagship software solution, has been designed from the ground up to take advantage of various technologies listed above to implement artificial intelligence and machine learning to enable automated advanced data extraction.
Our unstructured data extraction software ascertains patterns from document examples, truth data, and sample training, also known as machine learning. Take a look at our managed service overview, Axis Smart Data Extraction™ to understand how our solution can learn how to understand your unstructured content extraction requirements and automate information capture and data entry.